白話文告訴你 - 什麼是 PEFT 效率微調
目錄
非白話文的懶人包:
- 本篇介紹兩種微調法 – 以 transformer 起家,且要訓練的參數很少
- Prompt tuning: 在輸入文字的(embedding)前面多加 trainable 參數;用資料訓練 prompt engineering
- LoRA: 把原本模型做線性轉換的參數,多加一個同樣大小、但自由度較低 (low rank) 的 trainable 矩陣
名詞認識 #
模型訓練 #
假設一個外國人想學中文,但他什麼都不懂,是一張白紙
模型訓練 (model training) 是他從零開始,讀過大量教科書以後,總算把他的腦袋訓練成能夠看懂正常普通中文
微調 #
結果當他上批踢踢或 Threads,看到裡面的貼文推文:「那不就好棒棒」、「拜託電神鞭小力一點」這種次文化或流行詞,不知道是稱讚還是罵人
微調 (fine-tuning) 是給他看一些批踢踢/Threads的文章,並跟他解釋每一句是真實讚美還是明褒暗貶
「微調」也是訓練的一種,也是拿有答案的資料給他,只不過建立在「已經很不錯的模型之上」再專門學習特別的領域
(假設你知道類神經網路;文內的 AI 模型特指類神經網路)
比較技術一點:模型的參數一開始隨機不定,然後拿大量資料做第一批的訓練,得到 base model (基礎模型)
當有專門的目標(例如看懂推文語氣),「微調」是你拿該領域的資料:
- 以 base model 已經訓練好的參數為起點,繼續調整整個模型。或者
- 在 base model 附加簡易模型/參數,不動到原本模型參數 (freeze),只去訓練附加的參數
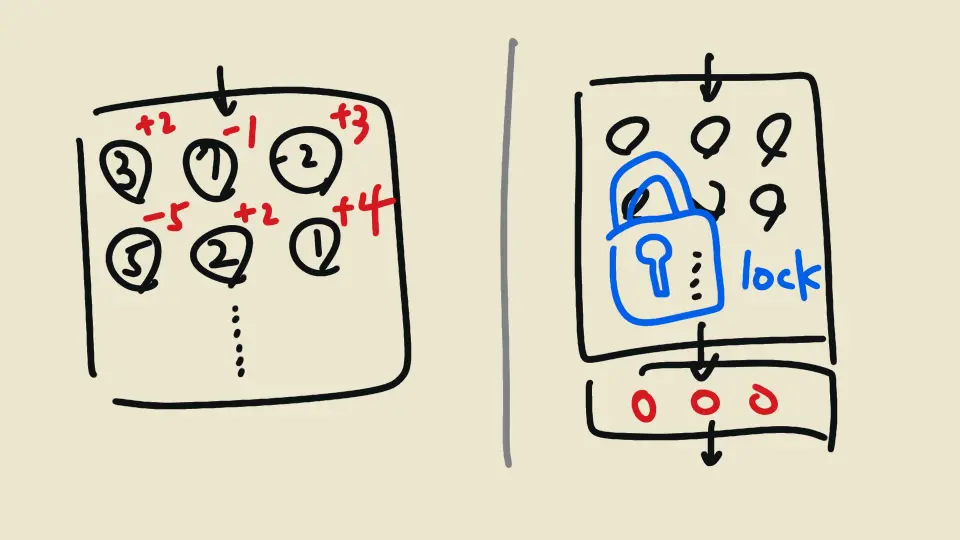
對於後者,以前常見的用法有:找一個很厲害的模型,在他輸出後多接一個小的分類器。利用 base model 分析出資料的精華特徵,「代表」這個資料後,再來做自己的訓練,而不是直接拿原始資料來訓練
而有一些微調方法,雖然也是凍結原本模型的參數,但並不是在輸出後附加自己的,而是保留 base model 原本的架構,在內部附加。
其中一個是 Prompt tuning, 還有一個是 LoRA
Prompt tuning #
Prompt engineering 最近變成顯學?例如跟 ChatGPT 說「請幫我摘要這段文字」「如果做得好就給你小費」或「做不好我有生命危險」。但是你怎麼知道這樣提示好不好?
這種人工嘗試錯誤、以人的智慧去發想的字詞,稱作 hard prompt
不過,機器學習/人工智慧的奧義就是把「人類發想的」改成用「資料去學習」。有人就想到讓模型接受輸入的文字時,前面先加一些克漏字空格當作 prompt
空格裡填什麼字才能讓機器人好好回答呢?我們不知道;我們拿微調的資料去訓練,讓模型去調整、改進空格里的內容,這叫 soft prompt
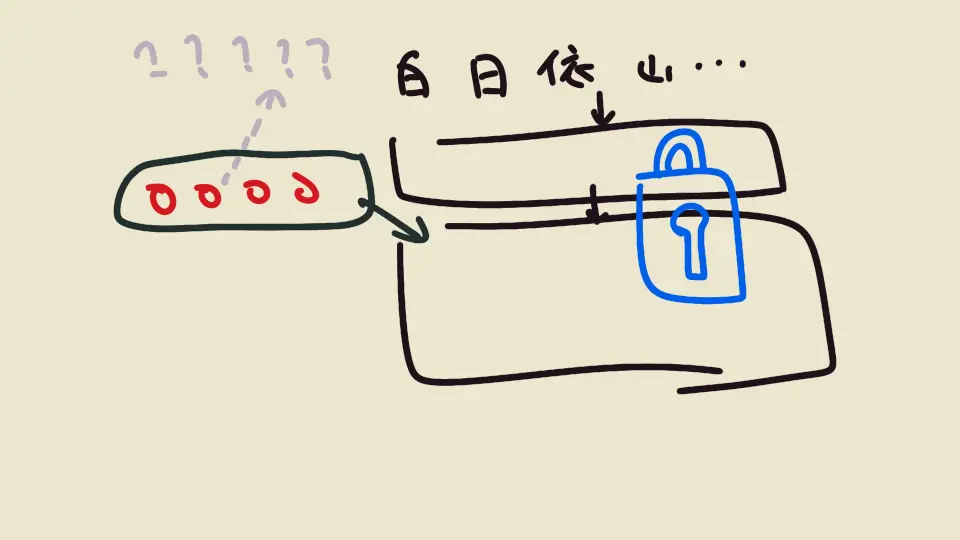
比較技術一點:他在輸入 token 變成的 embedding,往前拉長增加微調的參數。因為是 embedding,所以甚至無法對應回人看得懂的文字
LoRA #
LoRA 是在同樣的腦袋,同樣的模型上面去調整參數,乍看之下是改變全部的參數,但實際上調整的時候讓他自由度很低,不會很自由地胡思亂想
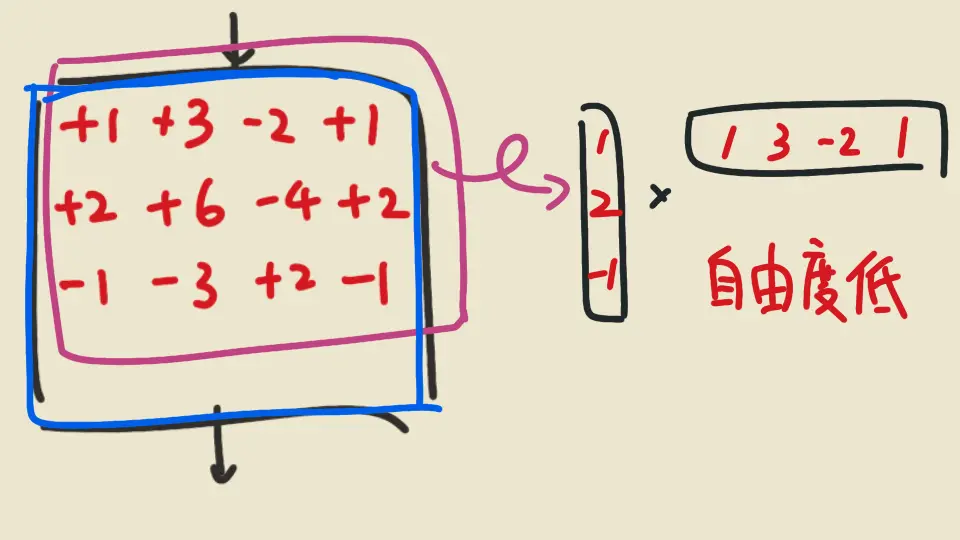
比較技術一點:模型裡面會有線性轉換的矩陣,微調的時候拿一個同樣大小的矩陣加法加上去,微調的時候只改加上去的矩陣;原來矩陣的值還是凍結不改
而這個拿來被改的矩陣,實際上是由兩個很扁,參數很少的矩陣相乘得出;調整參數是調整這兩個扁矩陣,所以調整的參數很少,但相對地能改動的自由度 (rank) 不大。不過根據實驗結果這已經足夠了
所以 LoRA 全名叫做 Low-Rank Adaptation, 這邊的 rank 是 matrix 的 rank (秩),也就是自由獨立的程度
PEFT #
PEFT 全名是 Parameter-Efficient Fine-Tuning,也就是微調很少的參數,有效率地達到不錯的效果,而不用整個模型重新訓練。
PEFT 也不只 prompt tuning 或 LoRA,有興趣的讀者可以參考 https://huggingface.co/docs/peft/index