抓別人的 GGUF 模型,用 Ollama 在本機執行!

目錄
在自己電腦跑別人的 GPT 模型 – 懶人包
記憶體不夠,但就差一點點? 看這
上一篇說過 Ollama 有官方與別人上傳的模型。但是,如果你聽說某個模型很厲害,在 Ollama 上卻找不到怎麼辦?
如果你能拿到模型的 GGUF 檔,也可以在本機用 Ollama 執行!(safetensors也可)
要找模型,除了發行組織的網站,最有可能就是存在 HuggingFace Hub 了!不過在說明怎麼下載之前,先稍微介紹 GGUF 是什麼
GGUF 是什麼 #
GGUF (GPT-Generated Unified Format) 是一種儲存模型權重的檔案格式,交給 GGML 基底的程式去推理/預測
本文不去追究 GGUF 詳細的知識,只是很精簡地列一下
- 特點:只有「一個」
.gguf檔 - 本身不是執行檔,需要另外特殊的執行程式去跑(例如 llama.cpp, Ollama 等等)
- PyTorch 訓練出來並非立即是 GGUF 檔,但可以轉檔成 GGUF
- GGUF 不一定代表量化 (quantize) 的模型,但同樣可用 llama.cpp 去量化變成 GGUF 檔

HuggingFace 有 GGUF 檢視器可以看裡面的資訊,像是 metadata 與每一層權重的維度
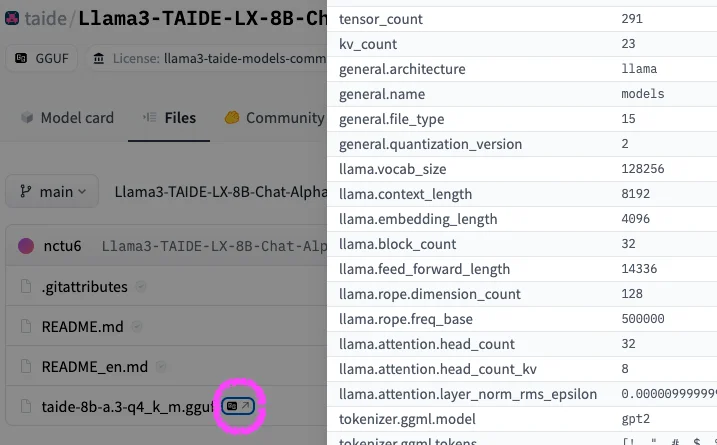
從 HuggingFace 下載模型 #
以台灣繁體大型語言模型 TAIDE 為例,他的 HuggingFace 在 https://huggingface.co/taide
因為我在 8G 的 Macbook Air 上測試,所以用他比較小的模型 Llama3-TAIDE-LX-8B-Chat-Alpha1-4bit
Gated model #
雖然不是每個模型都這樣,不過 TAIDE 需要你
- 在 HuggingFace 有個帳號並登入
- 填寫個人資料與授權同意書
才能夠使用(目前沒有審核時間,送出後馬上能用)
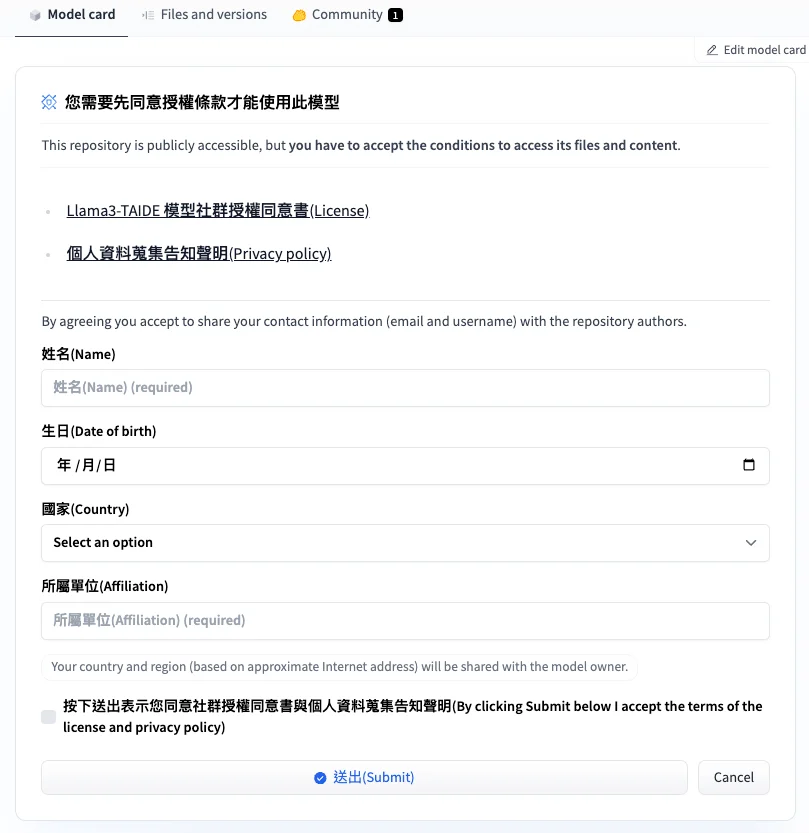
當你填寫完以後,有三種下載 TAIDE 模型的方法,任何一種都可以
下載方法一: Model 網頁按鈕 #
最簡單的就是同個 HuggingFace 模型的網頁,選 Files 以後,找到 .gguf 檔,旁邊會有個下載按鈕
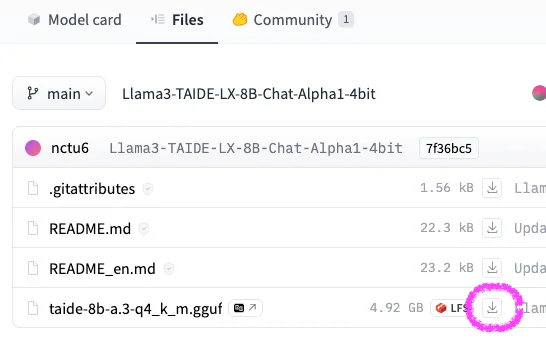
下載方法二: git #
可以用 git 下載,模型的 repo 其實是 git 的 repo
- (一次性) 把 ssh key 設定好(見後面)
- (一次性) 安裝 https://git-lfs.com/
- (一次性) 執行 git lfs install
- git clone 模型,例如
$ git clone [email protected]:taide/Llama3-TAIDE-LX-8B-Chat-Alpha1-4bit
因為要認證 git clone 的人是你,所以你要先在 HuggingFace 把 ssh key 設定好:
- 去右上角頭像進入設定 Settings,然後選 SSH and GPG Keys
- 把自己的 pubic key 加到上面即可。詳見這裡
下載方法三: huggingface 函式庫 #
git 會下載整個目錄。如果只想要下載某幾個檔案,或是有漂亮的進度條,可以用 huggingface_hub 函式庫
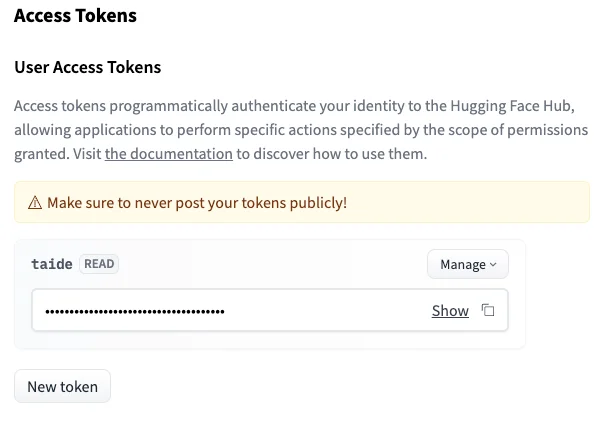
同樣因為要認證下載的是你,所以要先在 HuggingFace 設定好 access token: 去右上角頭像進入設定 Settings,然後選 Access Tokens
然後 pip install huggingface_hub , 再寫個小程式,並把剛剛的 token 加進去(不要 commit 到其他地方嘿)
from huggingface_hub import hf_hub_download
hf_hub_download(
repo_id="taide/Llama3-TAIDE-LX-8B-Chat-Alpha1-4bit",
token="<你的token在這啦>",
local_dir="my-hf-model",
filename="taide-8b-a.3-q4_k_m.gguf"
)
用 Ollama 執行 GGUF #
有 GGUF 檔以後,用 Ollama 執行它很簡單
- 在 GGUF 檔同個目錄,加一個檔案 Modelfile,裡面寫
FROM ./模型檔名.gguf
$ ollama create <你想要的模型名字> -f Modelfile
就這樣
Ollama 會把你的 gguf 檔案以他自己的架構放在 ~/.ollama/models/,也就是上一篇說過 Ollama 放模型的地方
- 如果你真的確定不需要原本的 gguf 檔的話,刪掉也是可以的
- 如果因為一些理由,你要把同個 gguf 檔包裝成多種不同模型的話,那些 tensor 權重內容在
~/.ollama/models/blobs/只會有一份:ollama 的模型有一點 docker cache 的味道
之後就可以用 ollama run <你想要的模型名字> 或 ollama serve, 總之等同於 Ollama 看得懂的模型了
不過,Modelfile 除了 FROM 告訴 Ollama 要包哪一個檔案以外,還有其他可能要設定的
TEMPLATE上一篇說過,怎麼把多輪對話塞成一長串 prompt,這跟模型怎麼訓練有關PARAMETER模型產生文字時的參數,詳見這裡num_keep是如果超過 context,那 prompt 要保留多少 token
- 其他指令見官方文件
TAIDE 這次的模型是拿 Llama3 為基底,所以我直接拿 Llama3 在 Ollama 上的的設定,再放到我的 Modelfile 裡面
有兩種方法拿到設定
ollama pull llama3下載 Llama3 以後,ollama show --modelfile llama3- 或者看 Ollama 網頁 Llama3 的 model card

所以最終我的例子是
$ cat Modelfile
FROM ./taide-8b-a.3-q4_k_m.gguf
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
PARAMETER num_keep 24
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
$ ollama create llama3-taide-chat-alpha1 -f Modelfile
$ ollama run llama3-taide-chat-alpha1
不過… 對我來說還少了一個東西
Ollama 噴亂碼 #
如果 ollama run 輸出亂碼,或是 ollama serve 在 non-stream 等了非常久都沒結果
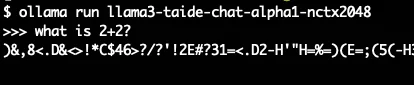
看一下 log ~/.ollama/logs/server.log,如果出現狂噴類似
...
ggml_metal_graph_compute: command buffer 3 failed with status 5
ggml_metal_graph_compute: command buffer 3 failed with status 5
ggml_metal_graph_compute: command buffer 3 failed with status 5
...
那大概就是記憶體不夠了!
在我的 Macbook Air m1 8G,跑 llama3 看到記憶體是剛剛好滿,跑 TAIDE 用 Llama3 微調的 Llama3-TAIDE-LX-8B-Chat-Alpha1-4bit 卻記憶體不夠,只差一點
不過沒問題,我在 Modelfile 加上一行
PARAMETER num_ctx 1024
調整 PARAMETER, 讓 inference 時的 context window 降低一點(預設 2048),就可以正常回答了!
