LangChain 與 LlamaIndex 比較 - RAG 多輪對話

目錄
這會是一系列的文章,從不同情境 use case 的實作去比較 LangChain 跟 LlamaIndex 的異同與優缺點,最後再總結
- Naive RAG
- Conversational RAG (這篇)
- Simple agent / tool use
- 人類半規範的 Agentic flow
- 總結 (敬請期待)
比較版本: LangChain 0.2.0 vs LlamaIndex 0.10.35
前一篇只考慮單次的一問一答。如果問第二個問題,AI 就像失憶:例如接著問「解釋更清楚一點」或「上一個問題怎麼解釋給小學生聽?」,LLM 不會知道你在問什麼,因為他不記得前一次的問答
在多輪對話中要用 RAG 有兩個挑戰
- 怎麼記得每一輪的問與答?
- 已經有多輪的問題跟答案了,那接下來面對使用者最新的問題,我要怎麼詢問資料庫?(單獨拿最新的問題?把所有的問題接起來?)
無論什麼框架,我採取 “condense + context” (或 question contextualization 意思一樣)
- 把歷史問答 + 新進來的問題用 LLM 「濃縮」成一個問題
- 拿濃縮過的問題,在資料庫中搜尋出相關資料,視作知識
- 把知識 + 歷史問答 + 新進來的問題交給 LLM 生成回答
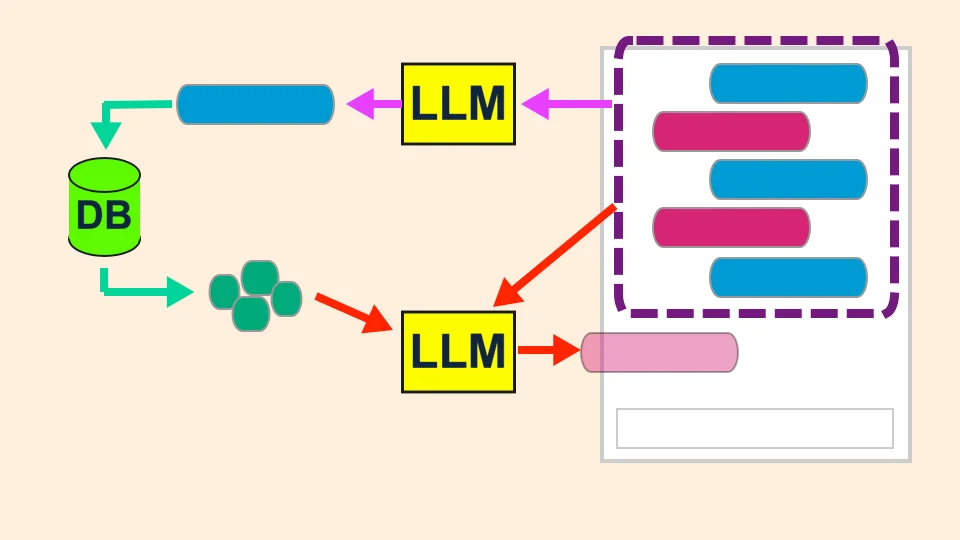
對於第一步讓我舉個例子。假設使用者跟 AI 有第一次問答:
人: 什麼是自由市場?
AI: 自由市場是一種經濟體系... (容我省略)
當使用者接著問 請解釋得能讓小學生聽得懂 時,我們希望第一步的 LLM 能彙整產生一個「問題」
(而不是回答問題):
你能用小孩子能聽得懂的方式解釋什麼是自由市場嗎?
實作比較 #
所有的實作都在這個 Github。餵資料的部分不變,所以建議比對 LangChain (la_rag.py) vs. LlamaIndex (ll_rag.py)
只看程式碼的最主要部分:
LangChain
# Condense (using LangChain's helper function)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, condense_prompt
)
# Answer (using 2 LangChain's helper function)
question_answer_chain = create_stuff_documents_chain(
llm, qa_prompt
)
rag_chain = create_retrieval_chain(
history_aware_retriever, question_answer_chain
)
# Manage chat message history for rag_chain
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
_get_memory,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)
print("====== conversation pass 1 ======")
response_1 = conversational_rag_chain.invoke(
input={"input": "要怎麼申請長照2.0?"},
config={
"configurable": {"session_id": "user-24601-conv-1337"}
}
)
LlamaIndex
...
memory = _get_memory("user-24601-conv-1337")
chat_engine = CondensePlusContextChatEngine.from_defaults(
retriever=retriever,
llm=llm,
memory=memory
)
print("====== conversation pass 1 ======")
response = chat_engine.chat("要怎麼申請長照2.0?")
print(response)
「LlamaIndex 贏了!好短!」
直接講這一句不夠公平,不過的確可以看出一些端倪
LlamaIndex 封裝 #
針對這個運用,LlamaIndex 封裝成一個主要的 class。而 RAG 各個元素,從基礎的 LLM, BaseRetriever, 到 VectorIndexRetriever, BaseNodePostprocessor 等等,
每種可能的要素都是一個類別。乍看之下會比較漂亮,或者有敘述性、比較好追蹤實作。
當然複雜度還是有的:每個 class 裡很多 has-a 關係,而且參數可能傳很深、**kwargs 到地下好幾層。
反之,LangChain 主體就是 chain (Runnable),你也是鏈子我也是鏈子,難一眼看出。而範例內看到好幾個 helper function,目的零碎,
如果不仔細追究很難知道為什麼這個 chain 配上那個 helper 會有這種作用。
也就是,LangChain helper function 太 “helper”、零碎、不夠敘述性,比較 write-only。這種拼裝方式可能會造成很陡的學習曲線
LlamaIndex 一條龍 + 細膩處理 #
LlamaIndex 內建提供了多種對話模式/邏輯, 內建彙整問答的 prompt 文字, 甚至還考慮如果 prompt 太長的話,歷史對話記錄要拿哪幾個給 LLM 生成回答。
LlamaIndex 可以說是從架上挑了喜歡的就走
LangChain 靠的則是強大的官方文件,把很多 use case 情境都整理出來,所以要抄也沒煩惱(這點 LlamaIndex 也一樣就是),但很多地方內建提供的不一定那麼細膩
題外話,LangChain 官方範例提供的 prompt 在我測試之下,第一步並沒有濃縮問題而是回答了問題 – 不過應該調整 prompt 就好,跟 LangChain 本身沒有太大的關係
LangChain magic key 外露 #
在我的 LangChain 範例可以看到一些寫死的 “key”,所謂的 magic 字串。
這是由於 LangChain 的某些設計,加上 LCEL Runnable 有種 functional language 的感覺(包括 partials / RunnablePassthrough …),在多變數函式寫起來很「字典」,外露 key 的名字,有些甚至寫死不能改。
LlamaIndex 也會,一般程式也會 – 只不過是化作函數的「參數名字」(signature) 跟物件的「成員變數名字」,大部分的情況下 IDE 都能正確推薦
客製化 #
無論是 LangChain 或 LlamaIndex 都能達到一定的客製化。LangChain 讓使用者拼裝的就不用說,以 LlamaIndex 的 CondensePlusContextChatEngine 為例,
在 constructor 傳進去的各個參數物件,像是 retriever, LLM, memory, prompt, …,都能自己選擇/實作。
總之他們就像樂高
- LangChain 是很多基礎的積木:身為 workflow engine ,讓開發者拼裝
- LlamaIndex 是一個產品包,且有不同功用的零件:注重 RAG 常見的情境
不過說到底,上面所講的全都偏向「寫程式喜好的風味」,倒也不是什麼致命的缺點。僅僅是 RAG 的話,我覺得了解抽象/整體的概念,遠比學什麼框架要重要得多
「聽起來你好像很推崇 LlamaIndex?」並不是!(還沒比較 serving 跟 instrumentation 呢)
如果想要作很複雜的流程,例如 RAG 回答後要讓 LLM 再自我反省呢?或是利用工具一步步拆解複雜問題呢?這就是 LangGraph 大顯身手的地方了!請看 下一篇的比較