LangGraph: LangChain Agent 的殺手鐧 (入門)

目錄
LangGraph 三部曲
- 入門: LangGraph 是什麼?
- 進階: LangGraph 的特點
- 範例: 用 LangGraph 解 LeetCode
LangGraph 是 LangChain 生態系 v0.2 主打的框架,也是實作 Agent 的建議。但 LangGraph 到底長怎麼樣?
「嘿兄弟,我好想交女朋友但都交不到,怎麼辦?」
身為 AI 工程師,為了幫他,當然是畫個流程圖啊!
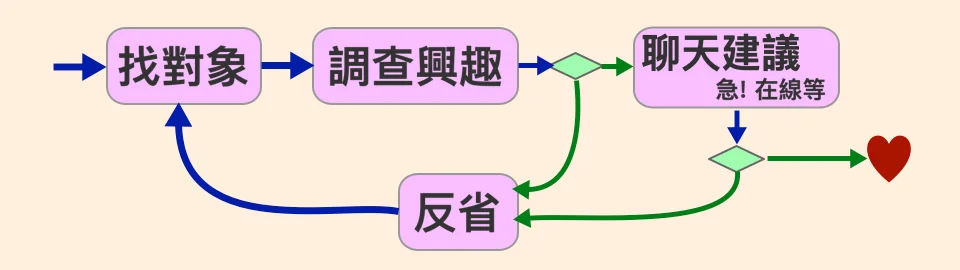
交女朋友要分步驟,每個步驟都有單一目的。如果失敗也沒關係,流程上我們退回去反省一下,再接再厲
「…這什麼?一點都不實際」
有道理,一定是因為沒有用 LangGraph 的關係!用了 LangGraph 一切都實際了起來
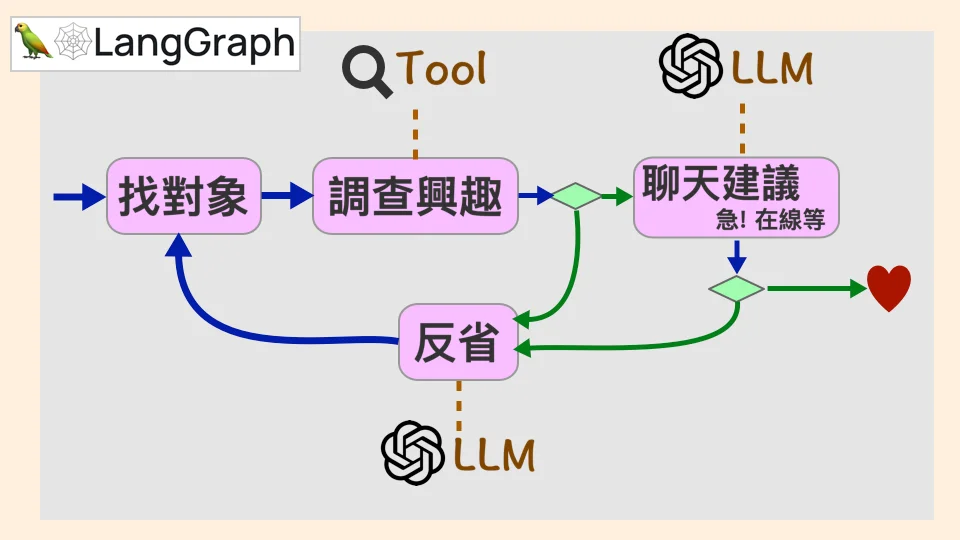
用 LangGraph 把每個步驟都接上 ChatGPT (LLM 語言模型)或者是工具(搜尋),要流程有流程,要行動有行動,這就是交友 agent 代理人
(… 那個,這只是例子,真實世界交友拜託拜託 請別這麼做 )
為什麼要 LangGraph? #
當你的產品需要一些流程、步驟,用 LangGraph 搭配 LangChain 能夠
- 實作出流程的運作
- 輕易把 LLM 引入每個步驟當中
- 把「流程」抽象出來,好維護。把每一個步驟複雜的實作封裝起來
可是,LangGraph 怎麼做到實踐流程呢?有三個元素
LangGraph 是什麼? #
LangGraph 像是「在 python 裡面寫另一個語言程式」:
- State: 如同變數表
- Node: 做事情 / function
- Edge: 流程控制
太抽象?給個簡單例子
# **State**
class MyState(TypedDict): # from typing import TypedDict
i: int
j: int
# Functions on **nodes**
def fn1(state: MyState):
print(f"Enter fn1: {state['i']}")
return {"i": 1}
def fn2(state: MyState):
i = state["i"]
return {"i": i+1}
# Conditional **edge** function
def is_big_enough(state: MyState):
if state["i"] > 10:
return END
else:
return "n2"
# The Graph! The "Program" !!
workflow = StateGraph(MyState)
workflow.add_node("n1", fn1)
workflow.add_node("n2", fn2)
workflow.set_entry_point("n1")
workflow.add_edge("n1", "n2")
workflow.add_conditional_edges(
source="n2", path=is_big_enough
)
# Compile, and then run
graph = workflow.compile()
r = graph.invoke({"i": 1000, "j": 123})
print(r)
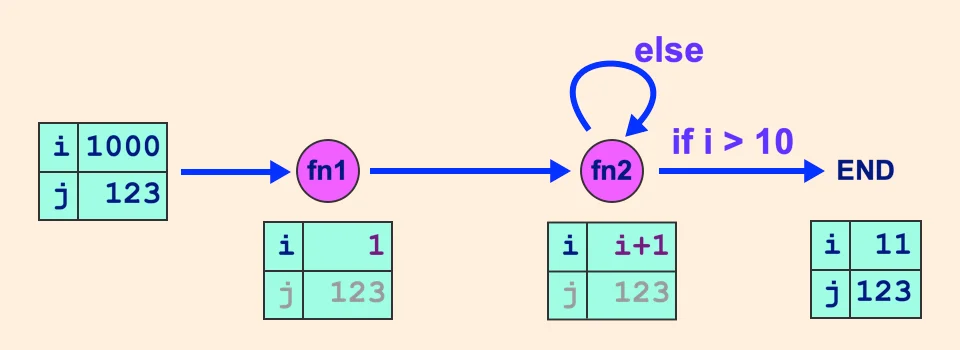
猜猜輸出長怎樣?
Enter fn1: 1000
{'i': 11, 'j': 123}
這其實很像下面這個 python 程式吧
i = 1
while True:
i += 1
if i > 10:
break
跟單純寫 python 程式的不同在,LangGraph 能夠讓每一個「步驟」都很複雜,引入 LLM 跟工具的處理,把「流程」抽象出來,變得乾淨好維護
Graph 像是一個程式 #
在這個例子 MyState 其實是一個字典,先知道這樣,後面有更多解釋
Node #
做事的是 fn1 跟 fn2 兩個 function,因為他們由 add_node() 綁在節點上 – 前面說了 Node 就是在做事
何謂做事?通常是「改變 state」
def fn1(state: MyState):
print(f"Enter fn1: {state['i']}")
return {"i": 1}
def fn2(state: MyState):
i = state["i"]
return {"i": i+1}
- 想像 state (狀態) 是屬於這個 graph 的「變數表」
fn1先印傳入的 state;回傳{"i": 1}代表「不管 state 的 i 以前是多少,現在覆蓋掉,變成 1 」- 同理,
fn2把 state 的 i 加上 1 以後回傳,代表「state 裡面的 i 多加 1 」- 注意
state["i"]是這個 graph 裡面的變數,在其他節點的 function 也能存取。但裸著的i是你這個 python 程式裡面的i,兩者不同。
- 注意
光是宣告 function 不夠,還要綁到 graph 上,給每個 node 一個名字
workflow.add_node("n1", fn1)
workflow.add_node("n2", fn2)
Edge #
執行順序呢?這就是 “edge” 控制了:從一個點有方向地連到另一個點
workflow.set_entry_point("n1")
workflow.add_edge("n1", "n2")
workflow.add_conditional_edges(
source="n2", path=is_big_enough
)
.set_entry_point()指定從哪個 node 開始執行.add_edge("n1", "n2")表示當 n1 執行完以後,下一步就交給 n2 執行- 寫程式的 “if” 用
.add_conditional_edges()達成,吃至少兩個參數source表示起點path是一個 function 決定下一步給誰:看他回傳的字串代表哪個 node- 我的範例
is_big_enough這個函數,去看 state 變數表裡的 i 有沒有大於 10,沒有的話就回傳 “n2”,也就是下一棒再交給自己。大於 10 的話就結束 (END)
def is_big_enough(state: MyState):
if state["i"] > 10:
return END
else:
return "n2"
所以整個 Graph 看起來像個小程式! 把 workflow 當作小程式碼、state 當作小變數表,compile 編譯成小執行檔
graph = workflow.compile()
r = graph.invoke({"i": 1000, "j": 123})
print(r)
- 整個 graph 需要
.compile()才是一個能執行的 graph。而 Compile 之後,後加的 node/edge 不會反映在上面 .invoke()是輸入初始的 state 去執行;輸出是最後的 state 長怎樣- 雖然所有節點都沒碰觸
j– 也就是回傳的都是 partial state ,但 state 的 schema 是 TypeDict, 裡面有宣告j,所以如果初始有給j值,也就這樣保留著,最後的輸出會有j
Enter fn1: 1000
{'i': 11, 'j': 123}
對了,有沒有發現:這範例完全沒 AI 模型。LangGraph 本質上就是個 “graph processing” engine 而已
State, state_schema, 跟 TypedDict #
有個最重要沒提的是:變數表怎麼宣告
from typing import TypedDict
from langgraph.graph import StateGraph
class MyState(TypedDict):
i: int
j: int
...
def fn2(state: MyState):
i = state["i"]
return {"i": i+1}
...
workflow = StateGraph(state_schema=MyState)
TypedDict 是 python 裡的一種型態宣告
- 用起來跟字典
dict一模一樣。只不過他預告有哪些 key 與其型態 - 例如範例中
MyState繼承TypedDict,只是闡述MyState是一個字典,「預期」會有 i 跟 j 兩個 key,而且值都是整數 - 實際執行的時候,少了 key 或多了 key ,是不是整數,都 不會報錯 (只是給型別檢查器看而已)
前面說的 workflow, 那些點啊線的,其實是一個 StateGraph 物件。創造時要跟他說 state 的型態 (state_schema)
等等,如果執行時不會報錯,為什麼還要 TypedDict (或者說,包一層 MyState)?
- 因為在創造
StateGraph物件時,你可以給 LangGraph 這個「預期」,跟他說這個 state 合法的 key 有這兩個 i 跟 j,其他不用理會 - 用
TypedDict宣告每個 key 的型態,還可以更進一步昭告 LangGraph 該怎麼「合併」(reduce) 同一個 key。 下一篇會詳細解釋
如果單純用 StateGraph(state_schema=dict),沒有預告,LangGraph 不知道每個 node 回傳的 key 重不重要,於是實作上會「很快忘記」那些 key :
如果某個步驟沒有回傳某個 key,下一步就會失去那個 key 的資訊。以我的範例來說,最後輸出不會有 j 了,因為 fn1 回傳的字典並沒有 j 這個 key,就會忘記 invoke 一開始傳進去的
workflow = StateGraph(state_schema=MyState)
.invoke({"i": 1000, "j": 123}) 後的結果是
{'i': 11, 'j': 123}
workflow = StateGraph(state_schema=dict)
.invoke({"i": 1000, "j": 123}) 後的結果是
{'i': 11}
雖然 state_schema 沒有限制型態,不過通常會是 TypedDict 或 pydantic.BaseModel。選擇這兩者在實際開發有些眉眉角角,詳見
下一篇
graph.stream() #
graph 除了 .invoke() 還可以 .stream(), 把每個 node 步驟「影響到的 state key」 的「結果」拿出來
(有點拗口,下一篇會解釋更詳細,現在就先當作是每個步驟的結果就好)
for s in graph.stream({"i": 1000}):
print(s)
會輸出
Enter fn1: 1000
{'n1': {'i': 1}}
{'n2': {'i': 2}}
... 太長了
{'n2': {'i': 10}}
{'n2': {'i': 11}}
兩個要注意的
- 這邊的 stream 不是「LLM token 一個個印出來」,而是指「一有 node 完成步驟就印出來」
- 他只會回傳影響到的 key,所以你不會看到 j
如果不用 .invoke() 又想在執行的途中拿到包括 j 的整個 state 要怎麼做?趕快看下一篇
其實,LangGraph 不只是在程式裡寫程式(否則就太遜了), 下一篇有 LangGraph 的特點:State reduce, persistence, 本質是什麼,用在 AI / LLM 上是怎麼回事,Human-in-the-loop, 還能做時間旅行!
但最重要的是我對 LangGraph 的感想,以及要不要用 LangGraph !?
前往 進階篇吧!
測試版本: LangGraph 0.0.65 (+LangChain 0.2.3) 抱怨一下,他們版本真的跑太快了