OpenAI 如何產生 Text Embedding -- Contrastive Learning
目錄
一句話形容 Contrastive Learning: 「分辨異同,而非辨認個體」
此為論文導讀: https://arxiv.org/abs/2201.10005 , Text and Code Embeddings by Contrastive Pre-Training
大數據是王道,但誰給正確答案? #
Self-supervised learning (自監督學習) 不需要人類標出答案,而是利用資料的性質,讓資料本身提供答案
LLM 的文字接龍就是這樣:一筆資料的答案是「下一個字」,所以資料有多大,答案就有多多,不被人類標答案的速度阻礙
而有一類 self-supervised learning 更奇特,他把多筆資料合成一組,學習目標是「分辨一組裡面的資料」,這叫做 Contrastive Learning (對比學習)
Contrastive Learning? 舉個例子? #
假設想辨認人臉誰是誰,準備了一堆人的照片,要怎麼訓練 AI 學習?
一種策略是單純的 multi-class classficiation 多類別的分類器,不過有兩個問題
- 很多人 (例如幾萬人的公司門禁)
- 新的人 (例如手機解鎖、出入境通關)
不可能每次有新的人就重新訓練整個模型(每天有多少新買 iphone 的人!)。就算要辨認的人是同一群,一個人 10 張照片當作一個類別,稀釋在幾萬個類別裡面,這種很不平衡的資料也很容易訓練失敗
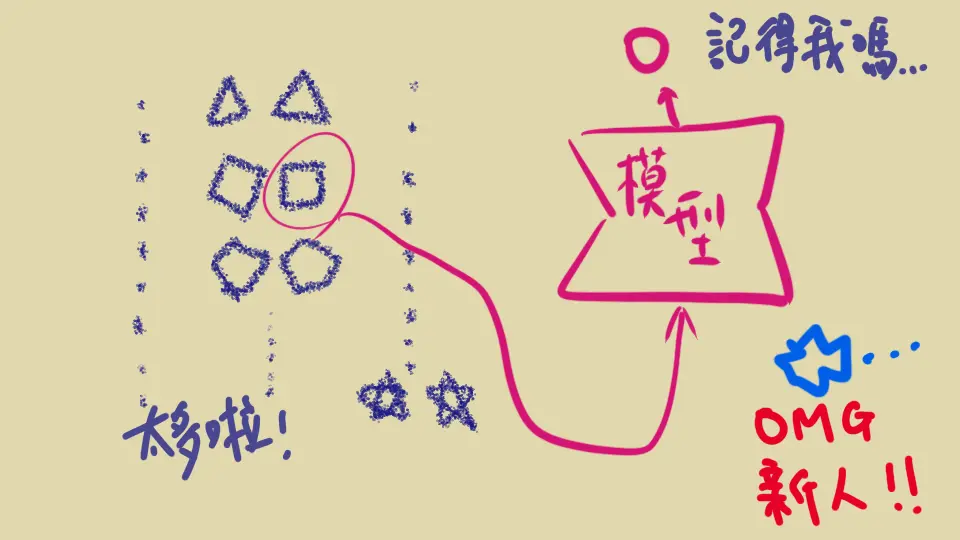
另一種策略: Contrastive learning , 則是去學習「比較兩張照片是否同一人」。也就是藉由學習「什麼會導致相同」「什麼會導致不同」,讓模型學到哪些特徵才是辨認人臉的要點,進而去算出數字代表這張臉
用「數字來表示一個東西」是不是很熟悉?這就是 我之前提過的 embedding
而以訓練的資料量來說,一個人能有多少張照片反而不是重點,重點在能否找到很多跟你不一樣的人
這能預測沒看過的照片是誰嗎?
可以的,只要有 A 的一張照片為基準,之後有新的照片 X 進來,讓模型告訴你「A 跟 X 是不是同一個人?」就好
如果有幾萬個人,以後辨認一張新的照片都要跑幾萬次預測?
不用!靠 embedding 就行
Embedding 跟 Contrastive Learning 的關係? #
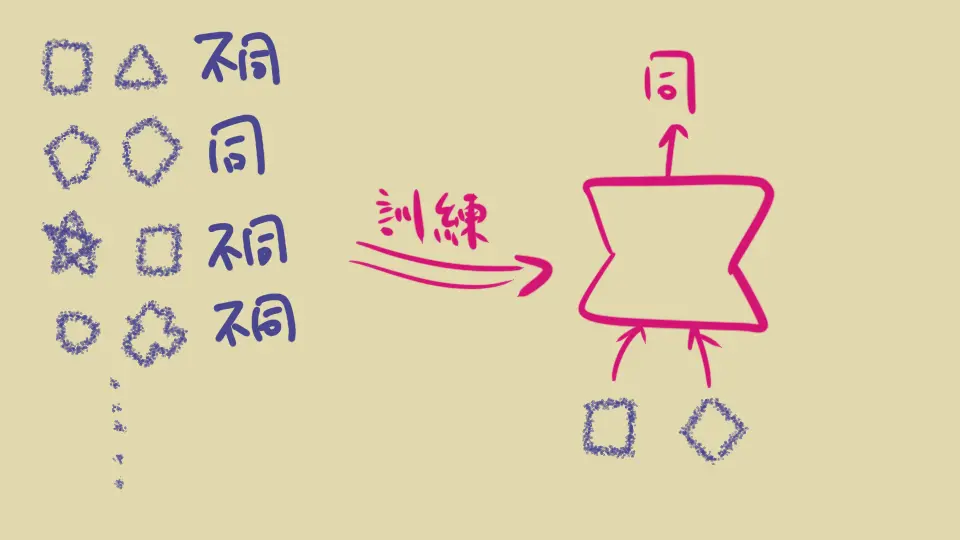
Contrastive Learning 的框架如下
- 模型架構:
- 讓模型對每一筆資料(例如一張照片)產生一個 embedding 向量
- 訓練的時候:
- 準備多筆資料,其中要有兩筆本質是一樣的(例如同一個人的兩張照片)稱作 positive pair. 也要有兩筆本質不一樣的(例如不同人的照片)稱作 negative pair
- 把這些資料餵給同一個模型,各別產生自己的 embedding 向量
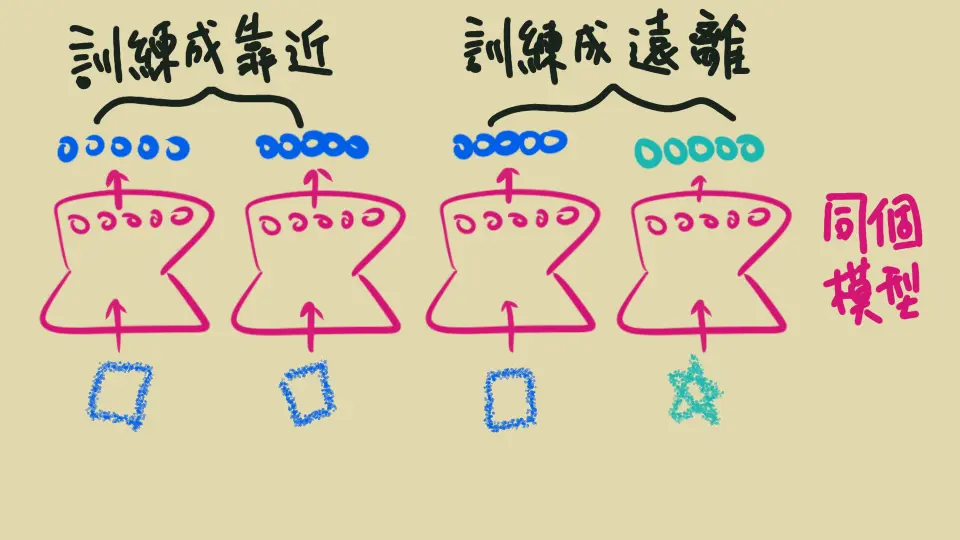
- 調整模型讓 positive 的兩筆資料 embedding 相近,negative 的兩筆相遠。遠近可以是 cosine similarity 或是距離等等
- 實際運用、預測新資料時:
- 讓模型算出他的 embedding 向量,就可以更進一步去做處理
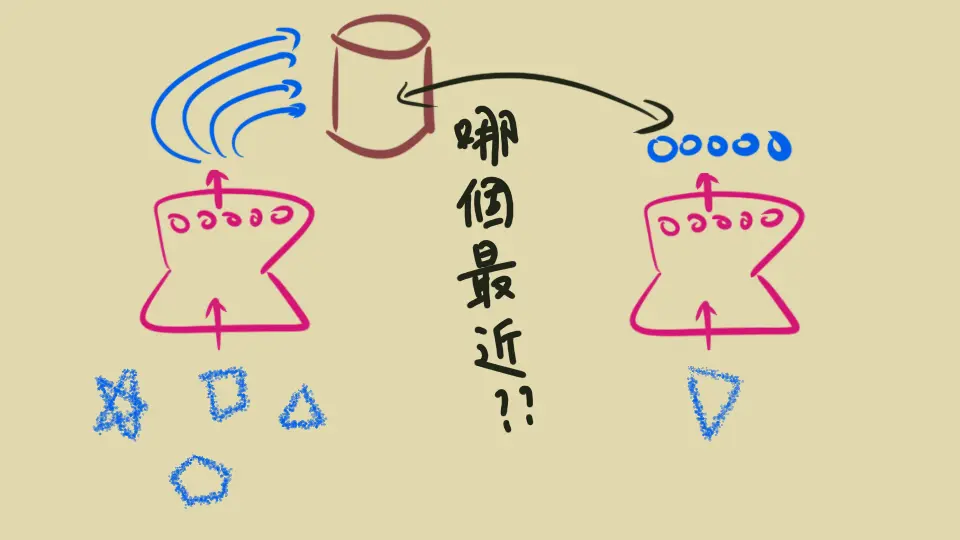
例如門禁系統:訓練出這種模型以後,先把一萬個員工的一張照片都算出 embedding 建檔,做一次就好。之後有人到門口就拍下來,算出「那一次」的 embedding,看他跟資料庫裡已知的一萬個 embedding 哪一個最相近(且相似度高不高),預測成他
而如果以後有新人,只要先照一張照片算出 embedding 來代表他就好,不用重新訓練模型:因為這個模型應該要有能力去「比較兩張照片是否為同一個人」,而不是「直接辨認出這個人是誰」 (請好好消化這一句話 lol)
辨認異同… 要怎麼訓練? #
既然模型目標是「辨認異同」,“loss function” 必須要能反映這個目標 – 所謂的 loss function 的是給模型的「懲罰」,我們希望模型被扣分得越少越好
以下舉兩個 Contrastive learning 會用到的 loss 的例子
1. Triplet Loss #
取三筆訓練資料 A, P, N,其中 A 跟 P 本質上是一樣的, positive pair (例如同一個人的兩張照片),而 A 跟 N 本質上不同, negative pair (例如兩個人的照片)
Triplet loss 的概念是要讓 A 跟 P 越近越好,A 跟 N 分得越開越好。公式寫成
$$ Loss = \max(0, sim(A,P) - sim(A,N) + \alpha) $$
其中 \( sim(.,.) \) 是模型算出來的相似度:訓練的時候希望模型算出來的相似度符合真實情況。 \(\alpha\) 是正數,事先固定取好的 (hyperparameter)
把 Loss 想成罰款,模型希望被罰的錢越少越好,這公式有兩個細節
- 模型不能裝皮皮,把所有的資料的 embedding 都算成同一個向量,讓隨便兩張照片相似度都是 0。最起碼會被罰 \(\alpha\) 元,除非模型很聰明能把 \(sim(A,P)\) 變小或 \(sim(A,N)\) 變大
- 有 max(0,) 擋著,做再好政府也不會貼給你錢,你做最好就是不罰錢而已,所以讓 \(sim(A,N)\) 超大也沒有用。分離的夠開就好
Triplet loss 的代表是 Google 的 FaceNet (2015) ,其中提到每次訓練步驟要選擇三筆也不簡單。隨便選很容易就不罰錢,沒學習到東西,所以為了讓模型能夠學習,要給他困難的挑戰:在 positive pair 裡面取比較遠的,negative pair 裡面取比較近的
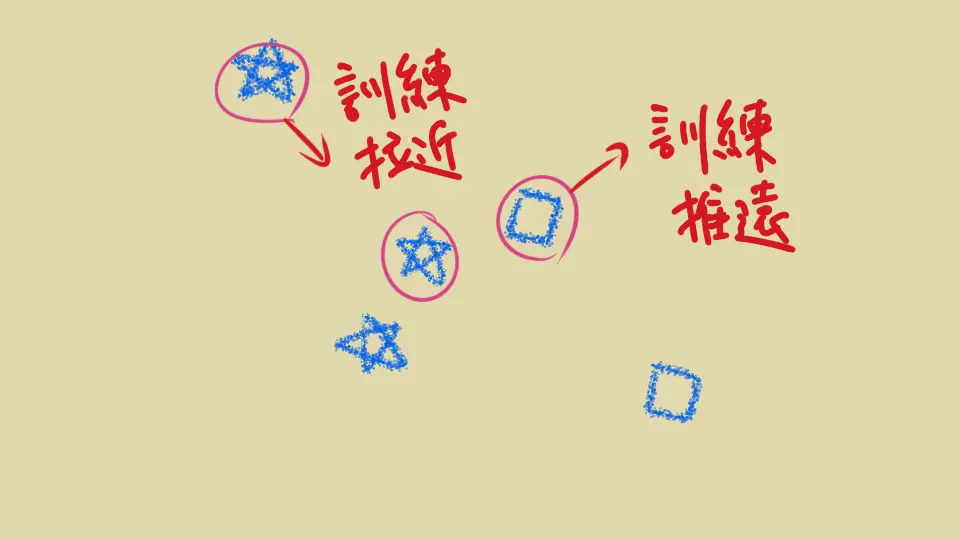
此外還有 online/offline 取法,在 batch 裡面找等等等,這邊就不詳述了
2. NT-Xent #
NT-Xent (Normalized Temperature-scaled CROSS ENTropy loss) 是 Google Research 在 2020 提出的 SimCLR 所提到(基於前人研究),跟 FaceNet 一樣也是為了影像做 embedding
概念上是每次 batch 裡面的資料都考慮進去,而不是挑選 triplet。假設 batch size 是 100
- 每一筆資料分生出兩筆(想像每一個人拿兩張照片;實作是用 augmentation)
- 一個 batch 裡面的資料,分生出來的 200 筆都會跟 loss 計算有關
- batch 裡的每一筆資料 A ,有他自己分生出來的,構成一對 positive pair
(A, A') - 其他跟 A 無關的,分生出來後的資料,都拿來當作 negative pair
(A, B_i)(例如會有 99 x 2 = 198 個 pair)
- batch 裡的每一筆資料 A ,有他自己分生出來的,構成一對 positive pair
- 想成 199 類別的問題:用 softmax 的想法算出「
A預測成A'positive 的機率」,配上 cross entropy loss - 分生後的 200 筆,每一筆都這樣算出 loss 然後平均
白話文就是:隨機挑出一群人,每個人照兩張照片,同一人的照片跟其他照片比較,要能脫穎而出,被預測出來是同一個人的
這邊附上原論文的公式(其中的 \(\tau\) 是 hyper parameter, 控制 simlarity 的大小會影響最後的 loss 的程度)

OpenAI 怎麼產生 Text embedding ? #
OpenAI 就是用 contrastive learning 打造(文字)Embedding 模型的 (well… 至少 2022 年發表的論文是這樣啦)
訓練資料 #
訓練資料是很多一對一對 (pair) 的文字。每一對文字 (x, y) 都是有關連的
- 網路上的文章:這一句
x跟下一句y湊成一對 - 程式碼:把一個 function
y跟他的 docstringx(function 的註解,非行內的) 湊成一對
題外話,在訓練資料裡面,會不會 “negative” pair 但從神的角度來看他們實際是 positive, 相似的呢?有可能,不過機率不高分佈不同,所以在大量的 in-batch negative pairs 之下趨勢還是對的
模型架構 #
- 模型是 Transformer 的 encoder
- 定義特別的兩個 token
[SOS]與[EOS];模型的輸入是一個句子用這兩個 token 夾起來,也就是[SOS]x[EOS]和[SOS]y[EOS]- 題外話,論文提到
x那邊的 token 跟y那邊的 token 用不同組的話,訓練比較穩定
- 題外話,論文提到
- 模型的輸出 embedding 是 encoder 最後一層對照的
[EOS]的 hidden state
Loss function #
跟 NT-Xent 類似,也有 \(\tau\) 代表溫度控制,也用 consine similarity。只不過 negative pair 只有取 x 或 y 的一邊(以最前面的例子來說,只有 99 個 negative pair 而不是 198 個)
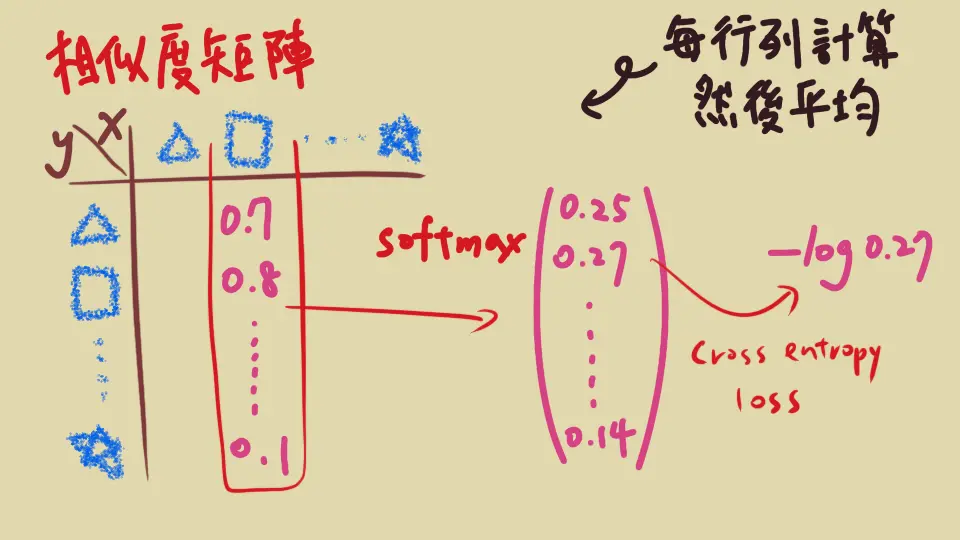
關鍵點 #
- 大 batch,也就是每一步的訓練都一次拿很多資料(例如幾千筆)
- 站在巨人的肩膀,用其他預訓練過的語言模型來初始化他們的模型。他們有提到光靠訓練資料是不夠的
那 OpenAI text embedding 可以幹嗎? #
Embedding 能用一串數字去代表抽象、離散的文字。這些數字有同等相似相異的關係,所以可以做很多事情囉
- 用人話
x描述,去找出程式碼y - 客人的問題
x,找到最相關的資訊y去回答 - 辨認客人的評論
x是稱讚還是負評y
這些都可以把 x 跟 y 的 embedding 向量算出來以後,去看彼此的距離近不近,回來表示這兩筆文字的語意、意思是否一樣
RAG (Retrieval Augmented Generation) 就是更進一步,把使用者的問題 x 找到相關連的一些資訊 y1, y2, ... 然後才交給 LLM 語言模型去整合回答,而不是靠 LLM 自由發揮
如果對 RAG 有興趣可以參考 站上相關文章唷